About this guide
This guide covers the use of exchanges according to the AMQP 0.9.1 specification including message publishing, common usage scenarios and how to accomplish typical operations using the Ruby amqp gem. This work is licensed under a Creative Commons Attribution 3.0 Unported License (including images and stylesheets). The source is available on Github.
Which versions of the amqp gem does this guide cover?
This guide covers Ruby amqp gem 1.5.x.
Exchanges in AMQP 0.9.1 - overview
What are AMQP exchanges?
An exchange accepts messages from a producer
application and routes them to message queues. They can be thought of as
the “mailboxes” of the AMQP world. Unlike some other messaging
middleware products and protocols, in AMQP, messages are not
published directly to queues. Messages are published to exchanges that
route them to queue(s) using pre-arranged criteria called
bindings.
There are multiple exchange types in the AMQP 0.9.1 specification, each with its own routing semantics. Custom exchange types can be created to deal with sophisticated routing scenarios (e.g. routing based on geolocation data or edge cases) or just for convenience.
Concept of bindings
A binding is an association between a queue
and an exchange. A queue must be bound to at least one exchange in order
to receive messages from publishers. Learn more about bindings in the
Bindings guide.
Exchange attributes
Exchanges have several attributes associated with them:
- Name
- Type (direct, fanout, topic, headers or some custom type)
- Durability
- Whether the exchange is auto-deleted when no longer used
- Other metadata (sometimes known as
x-arguments)
Exchange types
There are four built-in exchange types in AMQP v0.9.1:
- Direct
- Fanout
- Topic
- Headers
As stated previously, each exchange type has its own routing semantics and new exchange types can be added by extending brokers with plugins. Custom exchange types begin with “x-”, much like custom HTTP headers, e.g. x-recent-history exchange or x-random exchange.
Message attributes
Before we start looking at various exchange types and their routing
semantics, we need to introduce message attributes. Every AMQP message
has a number of attributes. Some attributes
are important and used very often, others are rarely used. AMQP message
attributes are metadata and are similar in purpose to HTTP request and
response headers.
Every AMQP 0.9.1 message has an attribute called
routing key. The routing key is an “address”
that the exchange may use to decide how to route the message . This is
similar to, but more generic than, a URL in HTTP. Most exchange types
use the routing key to implement routing logic, but some ignore it and
use other criteria (e.g. message content).
Fanout exchanges
How fanout exchanges route messages
A fanout exchange routes messages to all of the queues that are bound to it and the routing key is ignored. If N queues are bound to a fanout exchange, when a new message is published to that exchange a copy of the message is delivered to all N queues. Fanout exchanges are ideal for the broadcast routing of messages.
Graphically this can be represented as:

Declaring a fanout exchange
There are two ways to declare a fanout exchange:
- By instantiating an
AMQP::Exchangeand specifying the type as “:fanout” - By using the
AMQP::Channel#fanoutmethod
Here are two examples to demonstrate:
exchange = AMQP::Exchange.new(channel, :fanout, "nodes.metadata")
exchange = channel.fanout("nodes.metadata")
Both methods asynchronously declare a queue. Because the declaration
necessitates a network round-trip, publishing operations on
AMQP::Exchangeinstances are delayed until the broker
reply (exchange.declare-ok) is received.
Also, both methods let you pass a block to run a piece of code when the
broker responds with an exchange.declare-ok (meaning that the
exchange has been successfully declared).
channel.fanout("nodes.metadata") do |exchange|
# exchange is declared and ready to be used.
end
Fanout routing example
To demonstrate fanout routing behavior we can declare ten server-named exclusive queues, bind them all to one fanout exchange and then publish a message to the exchange:
exchange = channel.topic("amqpgem.examples.routing.fanout_routing", :auto_delete => true)
10.times do
q = channel.queue("", :exclusive => true, :auto_delete => true).bind(exchange)
q.subscribe do |payload|
puts "Queue #{q.name} received #{payload}"
end
end
# Publish some test data after all queues are declared and bound
EventMachine.add_timer(1.2) { exchange.publish "Hello, fanout exchanges world!" }
When run, this example produces the following output:
Queue amq.gen-0p/BjxGNCue42RcJhpUrdg received Hello, fanout exchanges world!
Queue amq.gen-3GXULvZuYh1KsOD83yvlNg received Hello, fanout exchanges world!
Queue amq.gen-4EcyydTfoZzXjNSSLsh09Q received Hello, fanout exchanges world!
Queue amq.gen-B1isyTpR5svB6ClQ2TQEBQ received Hello, fanout exchanges world!
Queue amq.gen-FwLLioB7Mk4LGA4yJ1Mo7A received Hello, fanout exchanges world!
Queue amq.gen-OtBQokiA/DmNkB5bPzaRig received Hello, fanout exchanges world!
Queue amq.gen-RYHQUrj3yihb0DRF7KVpRg received Hello, fanout exchanges world!
Queue amq.gen-SZJ40mGwbhdcbOGeHMhUkg received Hello, fanout exchanges world!
Queue amq.gen-sDeVZg9Vx1knq+n9EMi8tA received Hello, fanout exchanges world!
Queue amq.gen-uWOuVaosW4bWAHqKG6pZVw received Hello, fanout exchanges world!
Each of the queues bound to the exchange receives a copy of the message.
Full example:
#!/usr/bin/env ruby
# encoding: utf-8
require "bundler"
Bundler.setup
$:.unshift(File.expand_path("../../../lib", __FILE__))
require "amqp"
EventMachine.run do
AMQP.connect("amqp://dev.rabbitmq.com") do |connection|
channel = AMQP::Channel.new(connection)
exchange = channel.topic("amqpgem.examples.routing.fanout_routing", :auto_delete => true)
# Subscribers.
10.times do
q = channel.queue("", :exclusive => true, :auto_delete => true).bind(exchange)
q.subscribe do |payload|
puts "Queue #{q.name} received #{payload}"
end
end
# Publish some test data in a bit, after all queues are declared & bound
EventMachine.add_timer(1.2) { exchange.publish "Hello, fanout exchanges world!" }
show_stopper = Proc.new { connection.close { EventMachine.stop } }
Signal.trap "TERM", show_stopper
EM.add_timer(3, show_stopper)
end
end
Fanout use cases
Because a fanout exchange delivers a copy of a message to every queue bound to it, its use cases are quite similar:
- Massively multiplayer online (MMO) games can use it for leaderboard updates or other global events
- Sport news sites can use fanout exchanges for distributing score updates to mobile clients in near real-time
- Distributed systems can broadcast various state and configuration updates
- Group chats can distribute messages between participants using a fanout exchange (although AMQP does not have a built-in concept of presence, so XMPP may be a better choice)
Pre-declared fanout exchanges
AMQP 0.9.1 brokers must implement a fanout exchange type and pre-declare one instance with the name of “amq.fanout”.
Applications can rely on that exchange always being available to them. Each vhost has a separate instance of that exchange, it is not shared across vhosts for obvious reasons.
Direct exchanges
How direct exchanges route messages
A direct exchange delivers messages to queues based on a
message routing key, an attribute that every
AMQP v0.9.1 message contains.
Here is how it works:
- A queue binds to the exchange with a routing key K
- When a new message with routing key R arrives at the direct exchange, the exchange routes it to the queue if K = R
A direct exchange is ideal for the unicast routing of messages (although they can be used for multicast routing as well).
Here is a graphical representation:

Declaring a direct exchange
There are two ways to declare a direct exchange:
- By instantiating a
AMQP::Exchangeand specifying its type as “:direct” - By using the
AMQP::Channel#directmethod
Here are two examples to demonstrate:
exchange = AMQP::Exchange.new(channel, :direct, "nodes.metadata")
exchange = channel.direct("nodes.metadata")
Both methods asynchronously declare a queue. Because the declaration
necessitates a network round trip, publishing operations on
AMQP::Exchangeinstances are delayed until a broker reply
(exchange.declare-ok) is received.
Also, both methods let you pass a block to run a piece of code when the
broker responds with exchange.declare-ok (meaning that the exchange
has been successfully declared).
channel.direct("pages.content.extraction") do |exchange|
# exchange is declared and ready to be used.
end
Direct routing example
Since direct exchanges use the message routing key for routing, message producers need to specify it:
exchange.publish("Hello, direct exchanges world!", :routing_key => "amqpgem.examples.queues.shared")
The routing key will then be compared for equality with routing keys on bindings, and consumers that subscribed with the same routing key each get a copy of the message:
Full example:
#!/usr/bin/env ruby
# encoding: utf-8
require "bundler"
Bundler.setup
$:.unshift(File.expand_path("../../../lib", __FILE__))
require "amqp"
EventMachine.run do
AMQP.connect do |connection|
channel1 = AMQP::Channel.new(connection)
channel2 = AMQP::Channel.new(connection)
exchange = channel1.direct("amqpgem.examples.exchanges.direct", :auto_delete => true)
q1 = channel1.queue("amqpgem.examples.queues.shared", :auto_delete => true).bind(exchange, :routing_key => "shared.key")
q1.subscribe do |payload|
puts "Queue #{q1.name} on channel 1 received #{payload}"
end
# since the queue is shared, binding here is redundant but we will leave it in for completeness.
q2 = channel2.queue("amqpgem.examples.queues.shared", :auto_delete => true).bind(exchange, :routing_key => "shared.key")
q2.subscribe do |payload|
puts "Queue #{q2.name} on channel 2 received #{payload}"
end
# Publish some test data in a bit, after all queues are declared & bound
EventMachine.add_timer(1.2) do
5.times { |i| exchange.publish("Hello #{i}, direct exchanges world!", :routing_key => "shared.key") }
end
show_stopper = Proc.new { connection.close { EventMachine.stop } }
Signal.trap "TERM", show_stopper
EM.add_timer(3, show_stopper)
end
end
Direct exchanges and load balancing of messages
Direct exchanges are often used to distribute tasks between multiple workers (instances of the same application) in a round robin manner. When doing so, it is important to understand that, in AMQP 0.9.1, messages are load balanced between consumers and not between queues.
The Ruby amqp gem historically has a limitation that only one consumer
(message handler) is allowed per AMQP::Queue instance,
however, this limitation will be addressed in the future. With the amqp
gem 0.8.x, if you want to load balance messages between multiple
consumers in the same application/OS process, then you need to use a
separate channel for each of the consumers.
The Working With Queues and Patterns and Use Cases guides provide more information on this subject.
Pre-declared direct exchanges
AMQP 0.9.1 brokers must implement a direct exchange type and pre-declare two instances:
amq.direct""(empty string) exchange known asdefault exchange(unnamed, referred to as an empty string by many clients including amqp Ruby gem)
Applications can rely on those exchanges always being available to them. Each vhost has separate instances of those exchanges, they are not shared across vhosts for obvious reasons.
Default exchange
The default exchange is a direct exchange with no name (the amqp gem refers to it using an empty string) pre-declared by the broker. It has one special property that makes it very useful for simple applications, namely that every queue is automatically bound to it with a routing key which is the same as the queue name.
For example, when you declare a queue with the name of “search.indexing.online”, the AMQP broker will bind it to the default exchange using “search.indexing.online” as the routing key. Therefore a message published to the default exchange with routing key = “search.indexing.online” will be routed to the queue “search.indexing.online”. In other words, the default exchange makes it seem like it is possible to deliver messages directly to queues, even though that is not technically what is happening.
The amqp gem offers two ways of obtaining a reference to the default exchange:
- Using the
AMQP::Channel#default_exchangemethod - Using the
AMQP::Channel#directmethod with an empty string as the exchange name
AMQP::Exchange#initializecan also be used, but requires
more coding effort and it offers no benefits over instance methods on
AMQP::Channelin this particular case.
Some examples of usage:
exchange = AMQP::Exchange.new(channel, :direct, "")
exchange = channel.default_exchange
exchange = channel.direct("")
The default exchange is used by the “Hello, World” example:
#!/usr/bin/env ruby
# encoding: utf-8
require "rubygems"
require "amqp"
EventMachine.run do
AMQP.connect(:host => '127.0.0.1') do |connection|
puts "Connected to AMQP broker. Running #{AMQP::VERSION} version of the gem..."
channel = AMQP::Channel.new(connection)
channel.queue("amqpgem.examples.helloworld", :auto_delete => true).subscribe do |payload|
puts "Received a message: #{payload}. Disconnecting..."
connection.close { EventMachine.stop }
end
channel.direct("").publish "Hello, world!", :routing_key => "amqpgem.examples.helloworld"
end
end
Additionally, the routing example above can be rewritten to use the default exchange:
#!/usr/bin/env ruby
# encoding: utf-8
require "rubygems"
require "amqp"
EventMachine.run do
AMQP.connect do |connection|
channel1 = AMQP::Channel.new(connection)
channel2 = AMQP::Channel.new(connection)
exchange = channel1.default_exchange
q1 = channel1.queue("amqpgem.examples.queues.shared", :auto_delete => true)
q1.subscribe do |payload|
puts "Queue #{q1.name} on channel 1 received #{payload}"
end
q2 = channel2.queue("amqpgem.examples.queues.shared", :auto_delete => true)
q2.subscribe do |payload|
puts "Queue #{q2.name} on channel 2 received #{payload}"
end
# Publish some test data in a bit, after queues are declared & bound
EventMachine.add_timer(0.3) do
5.times { |i| exchange.publish("Hello #{i}, fanout exchanges world!", :routing_key => "amqpgem.examples.queues.shared") }
end
show_stopper = Proc.new { connection.close { EventMachine.stop } }
Signal.trap "TERM", show_stopper
EM.add_timer(3, show_stopper)
end
end
Direct exchange use cases
Direct exchanges can be used in a wide variety of cases:
- Direct (near real-time) messages to individual players in an MMO game
- Delivering notifications to specific geographic locations (for example, points of sale)
- Distributing tasks between multiple instances of the same application all having the same function, for example, image processors
- Passing data between workflow steps, each having an identifier (also consider using headers exchange)
- Delivering notifications to individual software services in the network
Topic exchanges
How topic exchanges route messages
Topic exchanges route messages to one or many queues based on matching between a message routing key and the pattern that was used to bind a queue to an exchange. The topic exchange type is often used to implement various publish/subscribe pattern variations.
Topic exchanges are commonly used for the multicast routing of messages.
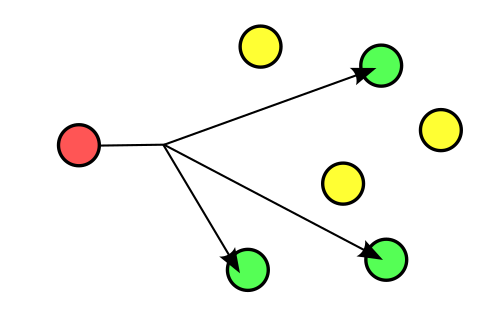
Topic exchanges can be used for broadcast routing, but fanout exchanges are usually more efficient for this use case.
Topic exchange routing example
Two classic examples of topic-based routing are stock price updates and
location-specific data (for instance, weather broadcasts). Consumers
indicate which topics they are interested in (think of it like
subscribing to a feed for an individual tag of your favourite blog as
opposed to the full feed). The routing is enabled by specifying a
routing pattern to the AMQP::Queue#bind method, for
example:
channel.queue("americas.south").bind(exchange, :routing_key => "americas.south.#").subscribe do |headers, payload|
puts "An update for South America: #{payload}, routing key is #{headers.routing_key}"
end
In the example above we bind a queue with the name of “americas.south”
to the topic exchange declared earlier using the
AMQP::Queue#bind method. This means that only messages
with a routing key matching americas.south.# will be routed to the
americas.south queue.
A routing pattern consists of several words separated by dots, in a similar way to URI path segments being joined by slash. A few of examples:
- asia.southeast.thailand.bangkok
- sports.basketball
- usa.nasdaq.aapl
- tasks.search.indexing.accounts
The following routing keys match the americas.south.# pattern:
- americas.south
- americas.south.**brazil**
- americas.south.**brazil.saopaolo**
- americas.south.**chile.santiago**
In other words, the “#” part of the pattern matches 0 or more words.
For the pattern “americas.south.**", some matching routing keys are:
- americas.south.**brazil**
- americas.south.**chile**
- americas.south.**peru**
but not
- americas.south
- americas.south.chile.santiago
As you can see, the * part of the pattern matches 1 word only.
Full example:
Topic exchange use cases
Topic exchanges have a very broad set of use cases. Whenever a problem involves multiple consumers/applications that selectively choose which type of messages they want to receive, the use of topic exchanges should be considered. To name a few examples:
- Distributing data relevant to specific geographic location, for example, points of sale
- Background task processing done by multiple workers, each capable of handling specific set of tasks
- Stocks price updates (and updates on other kinds of financial data)
- News updates that involve categorization or tagging (for example, only for a particular sport or team)
- Orchestration of services of different kinds in the cloud\
- Distributed architecture/OS-specific software builds or packaging where each builder can handle only one architecture or OS
Declaring/Instantiating exchanges
With the Ruby amqp gem, exchanges can be declared in two ways:
By using the
AMQP::Exchange#initializemethod that takes an optional callback- By using a number of convenience methods on
AMQP::Channelinstances:
- By using a number of convenience methods on
AMQP::Channel#default_exchangeAMQP::Channel#fanoutAMQP::Channel#directAMQP::Channel#topic
The previous sections on specific exchange types provide plenty of examples of how these methods can be used.
Publishing messages
To publish a message to an exchange, use
exchange.publish(payload, options)
The method accepts message body and a number of message and delivery metadata options. Routing key can be blank ("") but never nil.
The body needs to be a string. The message payload is completely opaque to the library and is not modified by Bunny or RabbitMQ in any way.
Data serialization
You are encouraged to take care of data serialization before publishing (i.e. by using JSON, Thrift, Protocol Buffers or some other serialization library). Note that because AMQP is a binary protocol, text formats like JSON largely lose their advantage of being easy to inspect as data travels across the network, so if bandwidth efficiency is important, consider using MessagePack or Protocol Buffers.
A few popular options for data serialization are:
- JSON: json gem (part of standard Ruby library on Ruby 1.9) or yajl-ruby (Ruby bindings to YAJL)
- BSON: bson gem for JRuby (implemented as a Java extension) or bson_ext for C-based Rubies
- Message Pack has Ruby bindings and provides a Java implementation for JRuby
- XML: Nokogiri is a swiss army knife for XML processing with Ruby, built on top of libxml2
- Protocol Buffers: beefcake
Message metadata
AMQP messages have various metadata attributes that can be set when a
message is published. Some of the attributes are well-known and
mentioned in the AMQP 0.9.1 specification, others are specific to a
particular application. Well-known attributes are listed here as options
that AMQP::Exchange#publish takes:
- :routing_key
- :persistent
- :mandatory
- :content_type
- :content_encoding
- :priority
- :message_id
- :correlation_id
- :reply_to
- :type
- :user_id
- :app_id
- :timestamp
- :expiration
All other attributes can be added to a headers table (in Ruby parlance, headers hash) that `AMQP::Exchange#publish } accepts as the “:headers” argument.
An example to show how message metadata attributes are passed to
AMQP::Exchange#publish:
exchange.publish("Hey, what a great view!",
:app_id => "amqpgem.example",
:priority => 8,
:type => "kinda.checkin",
:correlation_id => "b907b65a4876fc0d4b12fbdef1b41fb0a9876a94",
# headers table keys can be anything
:headers => {
:coordinates => {
:latitude => 59.35,
:longitude => 18.066667
},
:participants => 11,
:venue => "Stockholm"
},
:timestamp => Time.now.to_i,
:routing_key => "amqpgem.key")
- :routing_key
- Used for routing messages depending on the exchange type and configuration.
- :persistent
- When set to true, AMQP broker will persist message to disk.
- :mandatory
- This flag tells the server how to react if the message cannot be routed to a queue. If this flag is set to true, the server will return an unroutable message to the producer with a basic.return AMQP method. If this flag is set to false, the server silently drops the message.
- :content_type
- MIME content type of message payload. Has the same purpose/semantics as HTTP Content-Type header.
- :content_encoding
- MIME content encoding of message payload. Has the same purpose/semantics as HTTP Content-Encoding header.
- :priority
- Message priority, from 0 to 9.
- :message_id
- Message identifier as a string. If applications need to identify messages, it is recommended that they use this attribute instead of putting it into the message payload.
- :reply_to
- Commonly used to name a reply queue (or any other identifier that helps a consumer application to direct its response). Applications are encouraged to use this attribute instead of putting this information into the message payload.
- :correlation_id
- ID of the message that this message is a reply to. Applications are encouraged to use this attribute instead of putting this information\ into the message payload.
- :type
- Message type as a string. Recommended to be used by applications instead of including this information into the message payload.
- :user_id
- Sender’s identifier. Note that RabbitMQ will check that the [value of this attribute is the same as username AMQP connection was authenticated with](http://www.rabbitmq.com/extensions.html#validated-user-id), it SHOULD NOT be used to transfer, for example, other application user ids or be used as a basis for some kind of Single Sign-On solution.
- :app_id
- Application identifier string, for example, “eventoverse” or “webcrawler”
- :timestamp
- Timestamp of the moment when message was sent, in seconds since the Epoch
- :expiration
- Message expiration specification as a string
- :headers
- Ruby hash of any additional attributes that the application needs. Nested hashes are supported.
It is recommended that application authors use well-known message attributes when applicable instead of relying on custom headers or placing information in the message body. For example, if your application messages have priority, publishing timestamp, type and content type, you should use the respective AMQP message attributes instead of reinventing the wheel.
Validated user_id
In some scenarios it is useful for consumers to be able to know the identity of the user who published a message. RabbitMQ implements a feature known as validated User ID. If this property is set by a publisher, its value must be the same as the name of the user used to open the connection. If the user-id property is not set, the publisher’s identity is not validated and remains private.
Publishing callback and reliable delivery in distributed environments
Sometimes it is convenient to execute an operation after publishing a
message. For this, AMQP::Exchange#publish provides an
optional callback. It is important to clear up some expectations of when
exactly it is run and how it is related to topics of message delivery
reliability and so on.
exchange.publish(payload, :persistent => true, :type => "reports.done") do
# ...
end
A common expectation of the code above is that it is run after the message “has been sent”, or even “has been delivered”. Unfortunately, neither of these expectations can be met by the Ruby amqp gem alone. Message publishing happens in several steps:
AMQP::Exchange#publishtakes a message and various metadata attributesAMQP::Exchange#publishinternally calls #to_s on the message argument to get message payload- Resulting payload is staged for writing
- On the next event loop tick, data is transferred to the OS kernel using one of the underlying system calls (epoll, kqueue and so on) or NIO channels (in the case of JRuby)
- OS kernel buffers data before sending it
- Network driver may also employ buffering
Given all of this, you may ask ‘when does the
AMQP::Exchange#publish callback fire?’ The answer is on
the next event loop tick. By then the data is pushed down to the OS
kernel. As far as the Ruby library is concerned, it is reasonably safe
behavior.
In cases when you cannot afford to lose a single message, AMQP 0.9.1 applications can use one (or a combination of) the following protocol features:
- Publisher confirms (a RabbitMQ-specific extension to AMQP 0.9.1)
- Publishing messages as immediate and/or mandatory
- Transactions (these introduce noticeable overhead and have a relatively narrow set of use cases)
A more detailed overview of the pros and cons of each option can be found in a blog post that introduces Publisher Confirms extension by the RabbitMQ team. The next sections of this guide will describe how the features above can be used with the Ruby amqp gem.
Publishing messages as mandatory
When publishing messages, it is possible to use the “:mandatory” option to publish a message as “mandatory”. When a mandatory message cannot be routed to any queue (for example, there are no bindings or none of the bindings match), the message is returned to the producer.
The following code example demonstrates a message that is published as mandatory but cannot be routed (no bindings) and thus is returned back to the producer:
#!/usr/bin/env ruby
# encoding: utf-8
require "rubygems"
require 'amqp'
puts "=> Handling a returned unroutable message that was published as mandatory"
puts
AMQP.start(:host => '127.0.0.1') do |connection|
channel = AMQP.channel
channel.on_error { |ch, channel_close| EventMachine.stop; raise "channel error: #{channel_close.reply_text}" }
# this exchange has no bindings, so messages published to it cannot be routed.
exchange = channel.fanout("amqpgem.examples.fanout", :auto_delete => true)
exchange.on_return do |basic_return, metadata, payload|
puts "#{payload} was returned! reply_code = #{basic_return.reply_code}, reply_text = #{basic_return.reply_text}"
end
EventMachine.add_timer(0.3) {
10.times do |i|
exchange.publish("Message ##{i}", :mandatory => true)
end
}
EventMachine.add_timer(2) { connection.close { EventMachine.stop } }
end
Returned messages
When a message is returned, the application that produced it can handle that message in different ways:
- Store it for later redelivery in a persistent store
- Publish it to a different destination
- Log the event and discard the message
Returned messages contain information about the exchange they were
published to. For convenience, the amqp gem associates returned message
callbacks with AMQP::Exchange instances. To handle
returned messages, use AMQP::Exchange#on_return:
exchange.on_return do |basic_return, metadata, payload|
puts "#{payload} was returned! reply_code = #{basic_return.reply_code}, reply_text = #{basic_return.reply_text}"
end
A returned message handler has access to AMQP method (basic.return) information, message metadata and payload. The metadata and message body are returned without modifications so that the application can store the message for later redelivery.
Publishing persistent messages
Messages potentially spend some time in the queues to which they were routed before they are consumed. During this period of time, the broker may crash or experience a restart. To survive it, messages must be persisted to disk. This has a negative effect on performance, especially with network attached storage like NAS devices and Amazon EBS. AMQP 0.9.1 lets applications trade off performance for durability, or vice versa, on a message-by-message basis.
To publish a persistent message, use the :persistent option that
AMQP::Exchange#publishaccepts:
exchange.publish(payload, :persistent => true)
Durability and Message Persistence provides more information on the subject.
Publishing In Multi-threaded Environments
When using amqp gem in multi-threaded environments, the rule of thumb
is: avoid sharing AMQP::Channel instances across threads.
Starting with 0.8.0, AMQP::Exchange#publish
synchronizes data delivery on the channel object associated with
exchange. This protects application developers from the most common
problems related to publishing messages on a shared channel from
multiple threads, however, by no means protects from every possible
concurrency hazard.
Sending one-off messages
The following example publishes a message and safely closes the AMQP
connection afterwards by passing a block to
AMQP::Exchange#publish:
require 'rubygems' # or use Bundler.setup
require 'amqp'
puts "=> Publishing and immediately stopping the event loop in the callback"
puts
EventMachine.run do
connection = AMQP.connect(:host => '127.0.0.1')
channel = AMQP::Channel.new(connection)
# topic exchange is used just as example. Often it is more convenient to use default exchange,
# see http://bit.ly/amqp-gem-default-exchange
exchange = channel.topic("a.topic", :durable => true, :auto_delete => true)
queue = channel.queue("a.queue", :auto_delete => true).bind(exchange, :routing_key => "events.#")
exchange.publish('hello world', :routing_key => "events.hits.homepage", :persistent => true, :nowait => false) do
puts "About to unsubscribe..."
connection.close { EventMachine.stop }
end
end
Headers exchanges
Now that message attributes and publishing have been introduced, it is
time to take a look at one more core exchange type in AMQP 0.9.1. It is
called headersexchange type and is quite powerful.
How headers exchanges route messages
An example problem definition
The best way to explain headers-based routing is with an example. Imagine a distributed continuous integration system that distributes builds across multiple machines with different hardware architectures (x86, IA-64, AMD64, ARM family and so on) and operating systems. It strives to provide a way for a community to contribute machines to run tests on and a nice build matrix like the one WebKit uses. One key problem such systems face is build distribution. It would be nice if a messaging broker could figure out which machine has which OS, architecture or combination of the two and route build request messages accordingly.
A headers exchange is designed to help in situations like this by routing on multiple attributes that are more easily expressed as message metadata attributes (headers) rather than a routing key string.
Routing on multiple message attributes
Headers exchanges route messages based on message header matching.
Headers exchanges ignore the routing key attribute. Instead, the
attributes used for routing are taken from the headers attribute. When
a queue is bound to a headers exchange, the :arguments attribute is
used to define matching rules:
# when binding to a headers exchange, :arguments parameter is used to specify matching rules
@channel.queue("", :auto_delete => true).bind(exchange, :arguments => { :os => 'linux' })
When matching on one header, a message is considered matching if the value of the header equals the value specified upon binding. Using the example above, some messages that match would be:
exchange.publish "For linux/IA64", :headers => { :arch => "IA64", :os => 'linux' }
exchange.publish "For linux/x86", :headers => { :arch => "x86", :os => 'linux' }
exchange.publish "For any linux", :headers => { :os => 'linux' }
The following example demonstrates matching on integer values:
# consumer part
@channel.queue("", :auto_delete => true).bind(exchange, :arguments => { :cores => 8 })
# ...
# producer part
exchange.publish "For ocotocore", :headers => { :cores => 8 }
Matching on hashes (in AMQP 0.9.1 parlance - attribute tables) is also supported:
# consumer part
channel.queue("", :auto_delete => true).bind(exchange, :arguments => { :package => { :name => 'riak', :version => '0.14.2' } })
# ...
# producer part
exchange.publish "For nodes with Riak 0.14.2", :headers => { :package => { :name => 'riak', :version => '0.14.2' } }
Matching all vs matching one
It is possible to bind a queue to a headers exchange using more than one
header for matching. In this case, the broker needs one more piece of
information from the application developer, namely, should it consider
messages with any of the headers matching, or all of them? This is what
the x-match binding argument is for:
channel.queue("", :auto_delete => true).bind(exchange, :arguments => { 'x-match' => 'all', :arch => "ia64", :os => 'linux' })
In the example above, only messages that have an “arch” header value equal to “ia64” and an “os” header value equal to “linux” will be considered matching.
channel.queue("", :auto_delete => true).bind(exchange, :arguments => { 'x-match' => 'any', :os => 'macosx', :cores => 8 })
When the “x-match” argument is set to “any”, just one matching header value is sufficient. So in the example above, any message with a “cores” header value equal to 8 will be considered matching.
Declaring a headers exchange
There are two ways to declare a headers exchange:
- By instantiating
AMQP::Exchangeand specifying type as:headers - By using the
AMQP::Channel#headersmethod
Here are two examples to demonstrate:
exchange = AMQP::Exchange.new(channel, :headers, "builds")
exchange = channel.headers("builds")
Both methods asynchronously declare a queue. Because declaration
necessitates a network round trip, publishing operations on
AMQP::Exchange instances are delayed until the broker
reply (exchange.declare-ok) is received.
Both methods let you pass a block to run a piece of code when the broker
responds with exchange.declare-ok (meaning that the exchange has
been successfully declared).
channel.headers("builds") do |exchange|
# exchange is declared and ready to be used.
end
Headers exchange routing example
When there is just one queue bound to a headers exchange, messages are
routed to it if any or all of the message headers match those specified
upon binding. Whether it is “any header” or “all of them” depends on the
x-match header value. In the case of multiple queues, a headers
exchange will deliver a copy of a message to each queue, just like
direct exchanges do. Distribution rules between consumers on a
particular queue are the same as for a direct exchange.
Full example:
require 'rubygems'
require 'amqp'
puts "=> Headers routing example"
puts
AMQP.start do |connection|
channel = AMQP::Channel.new(connection)
channel.on_error do |ch, channel_close|
puts "A channel-level exception: #{channel_close.inspect}"
end
exchange = channel.headers("amq.match", :durable => true)
channel.queue("", :auto_delete => true).bind(exchange, :arguments => { 'x-match' => 'all', :arch => "ia64", :os => 'linux' }).subscribe do |metadata, payload|
puts "[linux/ia64] Got a message: #{payload}"
end
channel.queue("", :auto_delete => true).bind(exchange, :arguments => { 'x-match' => 'all', :arch => "x86", :os => 'linux' }).subscribe do |metadata, payload|
puts "[linux/x86] Got a message: #{payload}"
end
channel.queue("", :auto_delete => true).bind(exchange, :arguments => { :os => 'linux'}).subscribe do |metadata, payload|
puts "[linux] Got a message: #{payload}"
end
channel.queue("", :auto_delete => true).bind(exchange, :arguments => { 'x-match' => 'any', :os => 'macosx', :cores => 8 }).subscribe do |metadata, payload|
puts "[macosx|octocore] Got a message: #{payload}"
end
channel.queue("", :auto_delete => true).bind(exchange, :arguments => { :package => { :name => 'riak', :version => '0.14.2' } }).subscribe do |metadata, payload|
puts "[riak/0.14.2] Got a message: #{payload}"
end
EventMachine.add_timer(0.5) do
exchange.publish "For linux/ia64", :headers => { :arch => "ia64", :os => 'linux' }
exchange.publish "For linux/x86", :headers => { :arch => "x86", :os => 'linux' }
exchange.publish "For linux", :headers => { :os => 'linux' }
exchange.publish "For OS X", :headers => { :os => 'macosx' }
exchange.publish "For solaris/ia64", :headers => { :os => 'solaris', :arch => 'ia64' }
exchange.publish "For ocotocore", :headers => { :cores => 8 }
exchange.publish "For nodes with Riak 0.14.2", :headers => { :package => { :name => 'riak', :version => '0.14.2' } }
end
show_stopper = Proc.new do
$stdout.puts "Stopping..."
connection.close { EventMachine.stop }
end
Signal.trap "INT", show_stopper
EventMachine.add_timer(2, show_stopper)
end
Headers exchange use cases
Headers exchanges can be looked upon as “direct exchanges on steroids” and because they route based on header values, they can be used as direct exchanges where the routing key does not have to be a string; it could be an integer or a hash (dictionary) for example.
Some specific use cases:
- Transfer of work between stages in a multi-step workflow (routing slip pattern)\
- Distributed build/continuous integration systems can distribute builds based on multiple parameters (OS, CPU architecture, availability of a particular package).
Pre-declared headers exchanges
AMQP 0.9.1 brokers should (as defined by IETF RFC 2119) implement a headers exchange type and pre-declare one instance with the name of “amq.match”. RabbitMQ also pre-declares one instance with the name of “amq.headers”. Applications can rely on that exchange always being available to them. Each vhost has a separate instance of those exchanges and they are not shared across vhosts for obvious reasons.
Custom exchange types
x-random
The x-random AMQP exchange type is a custom exchange type developed as a RabbitMQ plugin by Jon Brisbin. To quote from the project README:
It is basically a direct exchange, with the exception that, instead of
each consumer bound to that exchange with the same routing key getting
a copy of the message, the exchange type randomly selects a queue to
route to.
This plugin is licensed under Mozilla Public License 1.1, same as RabbitMQ.
x-recent-history
The x-recent-history AMQP exchange type is a customer exchange type implemented as a RabbitMQ plugin by Alvaro Videla, one of the authors of RabbitMQ in action.
This plugin is licensed under the MIT license.
Using the Publisher Confirms extension to AMQP 0.9.1
Please refer to Vendor-specific extensions to AMQP 0.9.1 spec
Message acknowledgements and their relationship to transactions and publisher confirms
Consumer applications (applications that receive and process messages) may occasionally fail to process individual messages, or might just crash. Additionally, network issues might be experienced. This raises a question - "when should the AMQP broker remove messages from queues?" This topic is covered in depth in the Working With Queues guide, including prefetching and examples.
In this guide, we will only mention how message acknowledgements are related to AMQP transactions and the Publisher Confirms extension. Let us consider a publisher application (P) that communications with a consumer (C) using AMQP 0.9.1. Their communication can be graphically represented like this:
----- ----- -----
| | S1 | | S2 | |
| P | ====> | B | ====> | C |
| | | | | |
----- ----- -----
We have two network segments, S1 and S2. Each of them may fail. P is concerned with making sure that messages cross S1, while the broker (B) and C are concerned with ensuring that messages cross S2 and are only removed from the queue when they are processed successfully.
Message acknowledgements cover reliable delivery over S2 as well as successful processing. For S1, P has to use transactions (a heavyweight solution) or the more lightweight Publisher Confirms, a RabbitMQ-specific extension.
Using AMQP transactions
TBD
Binding queues to exchanges
Queues are bound to exchanges using the AMQP::Queue#bind
method. This topic is described in detail in the Working with
queues documentation guide.
Unbinding queues from exchanges
Queues are unbound from exchanges using the
AMQP::Queue#unbind method. This topic is described in
detail in the Working with queues
documentation guide.
Deleting exchange
Explicitly deleting an exchange
Exchanges are deleted using the AMQP::Exchange#delete
method:
exchange.delete
AMQP::Exchange#delete takes an optional callback that is
run when a exchange.delete-ok reply arrives.
exchange.delete do |delete_ok|
# by now exchange is guaranteed to be deleted
end
Auto-deleted exchanges
Exchanges can be auto-deleted. To declare an exchange as
auto-deleted, use the :auto_delete option on declaration:
exchange = AMQP::Exchange.new(channel, :direct, "nodes.metadata", :auto_delete => true)
exchange = channel.direct("nodes.metadata", :auto_delete => true)
Full example:
require 'amqp'
puts "=> Exchange#initialize example that uses :auto_delete => true"
puts
AMQP.start(:host => 'localhost', :port => 5673) do |connection|
AMQP::Channel.new do |channel, open_ok|
puts "Channel ##{channel.id} is now open!"
AMQP::Exchange.new(channel, :direct, "amqpgem.examples.xchange2", :auto_delete => false) do |exchange|
puts "#{exchange.name} is ready to go"
end
AMQP::Exchange.new(channel, :direct, "amqpgem.examples.xchange3", :auto_delete => true) do |exchange|
puts "#{exchange.name} is ready to go"
end
end
show_stopper = Proc.new do
$stdout.puts "Stopping..."
connection.close { EventMachine.stop }
end
Signal.trap "INT", show_stopper
EM.add_timer(2, show_stopper)
end
Objects as message producers.
Since Ruby is a genuine object-oriented language, it is important to demonstrate how the Ruby amqp gem can be integrated into rich object-oriented code. This part of the guide focuses on exchanges and the problems/solutions concerning producer applications (applications that primarily generate and publish messages, as opposed to consumers that receive and process them).
Full example:
#!/usr/bin/env ruby
# encoding: utf-8
require "rubygems"
require "amqp"
class Consumer
#
# API
#
def initialize(channel, queue_name = AMQ::Protocol::EMPTY_STRING)
@queue_name = queue_name
@channel = channel
@channel.on_error(&method(:handle_channel_exception))
end # initialize
def start
@queue = @channel.queue(@queue_name, :exclusive => true)
@queue.subscribe(&method(:handle_message))
end # start
#
# Implementation
#
def handle_message(metadata, payload)
puts "Received a message: #{payload}, content_type = #{metadata.content_type}"
end # handle_message(metadata, payload)
def handle_channel_exception(channel, channel_close)
puts "Oops... a channel-level exception: code = #{channel_close.reply_code}, message = #{channel_close.reply_text}"
end # handle_channel_exception(channel, channel_close)
end
class Producer
#
# API
#
def initialize(channel, exchange)
@channel = channel
@exchange = exchange
end # initialize(channel, exchange)
def publish(message, options = {})
@exchange.publish(message, options)
end # publish(message, options = {})
end
AMQP.start("amqp://guest:guest@dev.rabbitmq.com") do |connection, open_ok|
channel = AMQP::Channel.new(connection)
worker = Consumer.new(channel, "amqpgem.objects.integration")
worker.start
producer = Producer.new(channel, channel.default_exchange)
puts "Publishing..."
producer.publish("Hello, world", :routing_key => "amqpgem.objects.integration")
# stop in 2 seconds
EventMachine.add_timer(2.0) { connection.close { EventMachine.stop } }
end
Exchange durability vs Message durability
See Durability guide
Error handling and recovery
See Error handling and recovery guide
Vendor-specific extensions related to exchanges
See Vendor-specific Extensions guide
What to read next
Documentation is organized as several documentation guides that cover all kinds of topics. Guides related to this one are
- Durability and message persistence
- Bindings
- Patterns and Use Cases
- Working With Queues
- Error handling and recovery
Tell Us What You Think!
Please take a moment to tell us what you think about this guide on Twitter or the RabbitMQ mailing list
Let us know what was unclear or what has not been covered. Maybe you do not like the guide style or grammar or discover spelling mistakes. Reader feedback is key to making the documentation better.